Data Warehouse
Data Warehouse is a kind of data management system that is used as a main entity for business intelligence systems. This system contains enormous amounts of data and its job is to perform meaningful queries and analysis. For designing we have two approaches named Kimball model and Inmon model, both of which are described as follows:
Kimball:
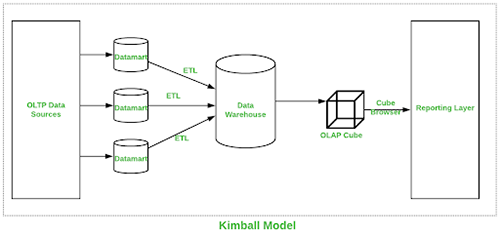
This approach was introduced by Ralph Kimball. Here the process of designing a data warehouse commences by understanding business process and queries the data warehouse system has to answer. For Kimball, the main concern is the performance on query execution and not disk space, so he uses a more denormalization form for modeling data.
The Extract Transform Load (ETL) procedures gathers data from various sources and club them into a common area called staging which is then transformed into OLAP cube (Several types of OLAP can be used).
Benefits of this process are as follows:
- • Quick to setup.
- • Successful reports generation against multiple star schema.
- • Effective operation.
- • Easy to manage and functional in less space.
- • Faster performance.
- • Uniformization.
Pictorial representation of Kimball Dataware house is shown below:
Inmon:
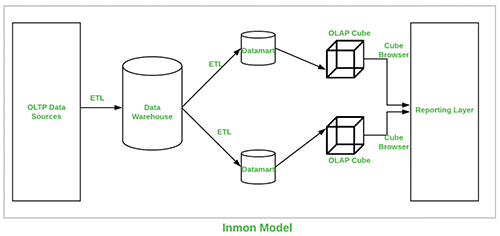
This approach was introduced by Bill Inmon and it commences with a corporate data model which identifies critical areas while keeping priority on the client, product and vendor. This model is successful for designing models utilized for major operations which is subsequently used to develop a physical model. The positive side of this model is that it is normalized and avoids data redundancy but its complex structure makes it difficult to be utilized for business motives for which data marts are created and each section of department is able to use it to their purposes.
Benefits of this process are as follows:
- • Open to changes.
- • Easy to understand.
- • Reduces disk Space.
- • Reports can be handled across enterprise.
- • ETL process less susceptible to errors.
Pictorial representation of Inmon Data warehouse is shown below:
Star schema:
In terms of data warehouse, under this concept we have a central fact table and various associated tables to that fact table. Such an arrangement resembles a star and this is how it derives its terminology. This is the simplest form of data warehouse schema and its best fit for querying enormous sets of data.
Constellations:
Moving ahead of star schema, where we have two fact tables, instead of one, and these fact tables have various associated tables. Such an arrangement resembles a constellation or a group of stars and that's why it's called constellation schema. Here, the shared dimensions are called conformed dimensions. The concept of conformed dimensions is explained in the next point.
Conformed dimension:
By conformed dimensions we mean those dimensions that are developed in such a manner that they can be used across multiple fact tables in various subject areas of data warehouse. Conformed dimensions yields reporting consistency across subject areas which in turn lowers down development costs of those subject areas by reusing the existing dimensions. The best example of conformed dimension is date dimension as most warehouses only have single date dimension which can be used across the warehouse.
Dimensions:
In the area of data warehouse, the term dimensions signifies a group of reference information about measurable events, which are known as facts. These dimensions classify and explain data warehouse facts and gauze it in a meaningful manner that answers business queries. Dimensions can be called upon as the core of dimensional modelling.
Fact tables:
Fact tables are the central entity in the star schema of a data warehouse. A fact table is used to store quantitative information for various forms of inspection and is often denormalized. A fact table is functional with dimension tables and it guards the data to be examined whereas a dimension table guards data about the methods in which data can be examined and analyzed.
Data management:
A procedure that includes ingesting, saving, assembling and preserving the valuable set of data that is both collected and generated by an organization. Data management plays an important role in installing IT systems that helps an organization in their decision making and strategic planning by managers and end users.
Effective data management is dependent on the following factors.
Data quality:
Here we measure the state of the date on various factors like correctness of the data, its integrity and if it is generated consistently or not. These factors play an important role in deciding the quality of data that can be in turn used for running various applications.
Data profiling:
The second important factor is to review the source from where data is generated, knowing its structure, its content, its relationships with other data sources and understanding how this data can help with our projects. This analysis helps us save time on identifying problems and designing solutions.