Data Warehouse
Data Warehouse é um tipo de sistema de gestão de dados que é usado como entidade principal para sistemas de business inteligence. Este sistema contém uma enorme quantidade de dados e a sua função é realizar consultas e análises de grande importância. Para o design temos duas abordagens que são o modelo Kimball e o modelo Inmon, que são descritos da seguinte forma:
Kimball:
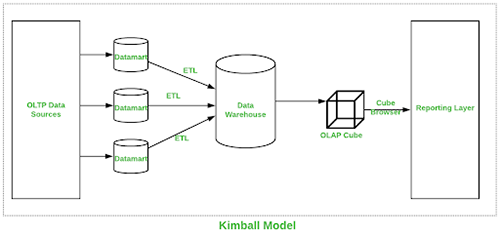
Esta abordagem foi introduzida por Ralph Kimball. Aqui, o processo para desenvolver uma data warehouse começa em perceber processos de negócio e consultas a que o sistema data warehouse tem de responder. Para Kimball, a maior preocupação é o desempenho em execução de consultas em vez do espaço no disco, então ele usa uma forma de denormalização para a modelagem de dados.
O procedimento Extract Transform Load (ETL) junta dados de ume variedade de fontes e agrupa-as numa área comum chamada staging que é depois transformada num cubo OLAP (Vários tipos de OLAP podem ser usados).
Estes são os benefícios deste processo:
- • Setup rápido.
- • Geração bem-sucedida de relatórios em múltiplos esquemas estrela.
- • Operação eficaz.
- • Fácil utilização e funcional com menos espaço.
- • Desempenho mais rápido.
- • Uniformização.
Representação visual da Kimball Data Warehouse abaixo:
Inmon:
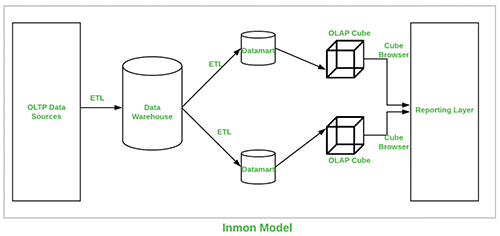
Esta abordagem foi introduzida por Bill Inmon e começa com um modelo de dados corporativo que identifica áreas críticas enquanto mantém a prioridade no cliente, produto e vendedor. Esta abordagem tem sucesso no desenvolvimento de modelos utilizados para operações de grande importância que depois são usados para desenvolver um modelo físico. O lado positivo desta abordagem é que ela é normalizada e evita redundância de dados, mas a sua estrutura complexa faz com que seja difícil de utilizar em objetivos de negócio para os quais são criados data marts, e cada secção de departamento é capaz de a utilizar para os seus objetivos.
Estes são os benefícios deste processo:
- • Aberto a mudanças.
- • Fácil de entender.
- • Reduz o espaço no disco.
- • Relatórios podem ser usados por toda a empresa.
- • Processo ETL menos suscetível a erros..
Representação visual da Inmon Data Warehouse abaixo::
Esquema estrela:
No que toca a data warehouse, dentro deste conceito temos uma tabela de factos central e várias tabelas associadas a essa tabela de factos. Este tipo de organização parece uma estrela, daí a sua terminologia. Esta é a forma esquemática mais simples de data warehouse e serve principalmente para a consulta de quantidades enormes de dados.
Constelações:
Vai além do esquema estrela, porque aqui temos duas tabelas de factos em vez de uma, e estas tabelas de factos têm várias tabelas associadas de forma a que a sua organização parece uma constelação ou grupo de estrelas, e é por esse motivo que se chama um esquema constelação. Aqui, as dimensões partilhadas são denominadas dimensões conformes. O conceito de dimensões conformes será explicado no próximo ponto.
Dimensões conformes:
Por dimensões conformes queremos dizer aquelas dimensões que são desenvolvidas de uma forma em que podem ser utilizadas em várias tabelas de factos e muitas áreas temáticas de data warehouse. Dimensões conformes ajudam na consistência de relatórios em várias áreas temáticas, o que baixa os custos de desenvolvimento dessas áreas ao reutilizar as dimensões existentes. O melhor exemplo de dimensões conformadas é dimensão de dados visto que a maior parte das warehouses tem uma única dimensão de dados que pode ser usada por toda a warehouse.
Dimensões:
Na área de data warehouse, o termo dimensão significa um grupo de informações de referência acerca de um evento mensurável que são conhecidas como factos. Estas dimensões classificam e explicam factos de data warehouse e analisam-nos de forma significativa para que respondam a consultas de negócios. As dimensiões podem ser referidas como o centro da modelagem dimensional.
Tabelas de factos:
As tabelas de factos são as entidades centrais num esquema estrela de uma data warehouse. Uma tabela de factos é usada para guardar informação quantitativa para variadas formas de inspeção e geralmente é desnormalizada. Uma tabela de factos é funcional com tabelas de dimensão e guarda os dados a serem examinados, enquanto que uma tabela de dimensão guarda dados sobre os métodos em que a informação pode ser examinada e analisada.
Data management:
Um procedimento que inclui ingestão, armazenamento, montagem e preservação do valioso conjunto de dados que é tanto coletado como gerado por uma organização. Data management tem um papel importante na instalação de sistemas IT que ajudam uma organização nos seus processos de tomada de decisões e planeamento estatégico por parte dos seus managers e consumidores.
Data management eficiente está dependente dos seguintes fatores:
Data quality:
Aqui, calculamos o estado de vários fatores como a exatidão dos factos, a sua integridade e se é gerada consistentemente ou não. Estes fatores têm um papel importante para decidir a qualidade dos dados que podem ser então usados para executar várias aplicações.
Data profiling:
O segundo fator importante é a revisão da fonte de onde os dados são gerados, conhecimento da sua estrutura, do seu conteúdo, das suas relações com outras fontes de dados e o entendimento de como estes dados nos podem ajudar nos nossos projetos. Esta análise ajuda-nos a poupar tempo na identificação de problemas e desenvolvimento de soluções.